Table of Contents
APIC Controller Cluster
You actually need three APIC controller servers to get the cluster up and running in complete and redundant ACI system. You can actually work with only two APICs and you will still have a cluster quorum and will be able to change ACI Fabric configuration.
Loosing One Site
In the MultiPod, those three controllers need to be distributed so that one of them is placed in the secondary site. The idea is that you still have a chance to keep your configuration on one remaining APIC while losing completely primary site with two APICs. On the other hand, if you lose secondary site, two APICs in the first site will still enable you to do configuration and management of ACI Fabric as nothing happened.
Losing DCI Interconnect
The second type of MultiPod fail is when you lose DCI (datacenter interconnect). In that case, both sites will keep working but will alert that the other side is down. The secondary site with one APIC will be in read-only mode and the primary site will be fully functional with two remaining APICs on that site. If some changes are made on the primary site, those changes will be replicated to the third controller on the secondary site when DCI recovers and configuration relating site B POD will be then pushed to POD 2 fabric.
DCI issues are not a good time for APIC replacement, just wait for DCI to start working normally and continue to use ACI APIC controllers as before the issues. You will still have the option to manage primary site if DCI fails and after DCI starts working again changes will be replicated to secondary site APICs and Fabric.
Please note that temporary DCI issues are not a good time to replace the APIC. If you are experiencing just a DCI outage the second site still works but it cannot be configured. Think about it, perhaps the best thing to do in this case is not to change the configuration of your fabric on either side while DCI doesn’t get back up and running. That way you are sure your configuration does not affect the MultiPod stability once DCI gets back up and sites start to communicate again.
More Than Three APICs
If your Fabric is huge, you will need to use 5 member APIC cluster which is able to manage altogether more than 300 Leaf Switches. In that case, you have an issue with shreds of the database that keeps your configuration. In 5 controller cluster, some of the APICs will keep only some of the ACI Fabric configuration and not a whole copy like in three cluster member setup. You should keep in mind that having more APICs will not make your cluster more robust, it will only get more power to manage more leafs.
Here you have more info about 3 vs 5 cluster members and some more scalability info.
Standby APIC Controller
In three cluster member setup, it is recommended to use one more APIC (fourth one) on the secondary site in order to be able to recover in fully functional mode even if the primary site with two active cluster members gets completely down and gets lost altogether due to some unexpected fire, flood or construction fail.
In case of normal datacenter operation, the fourth APIC will be in standby mode which means that it will keep whole ACI Fabric configuration but it will not be reachable via https nor will he take part of cluster quorum calculation. It will just sync the tenant configuration shreds from other APICs and it will also be automatically updated when cluster software is updated.
He will just wait there for some disaster to happen so that network admins can take leverage of his existence and promote the APIC to the active one.
In order to start using the standby cluster member, after the primary site is lost, you need to go through APIC replace method that will replace one of the lost APICs with standby. Standby APIC will then become active and it will take the ID of the lost one. His IP address will not change in that process nor will he change his name.
Replacing Lost Active APIC with Standby APIC
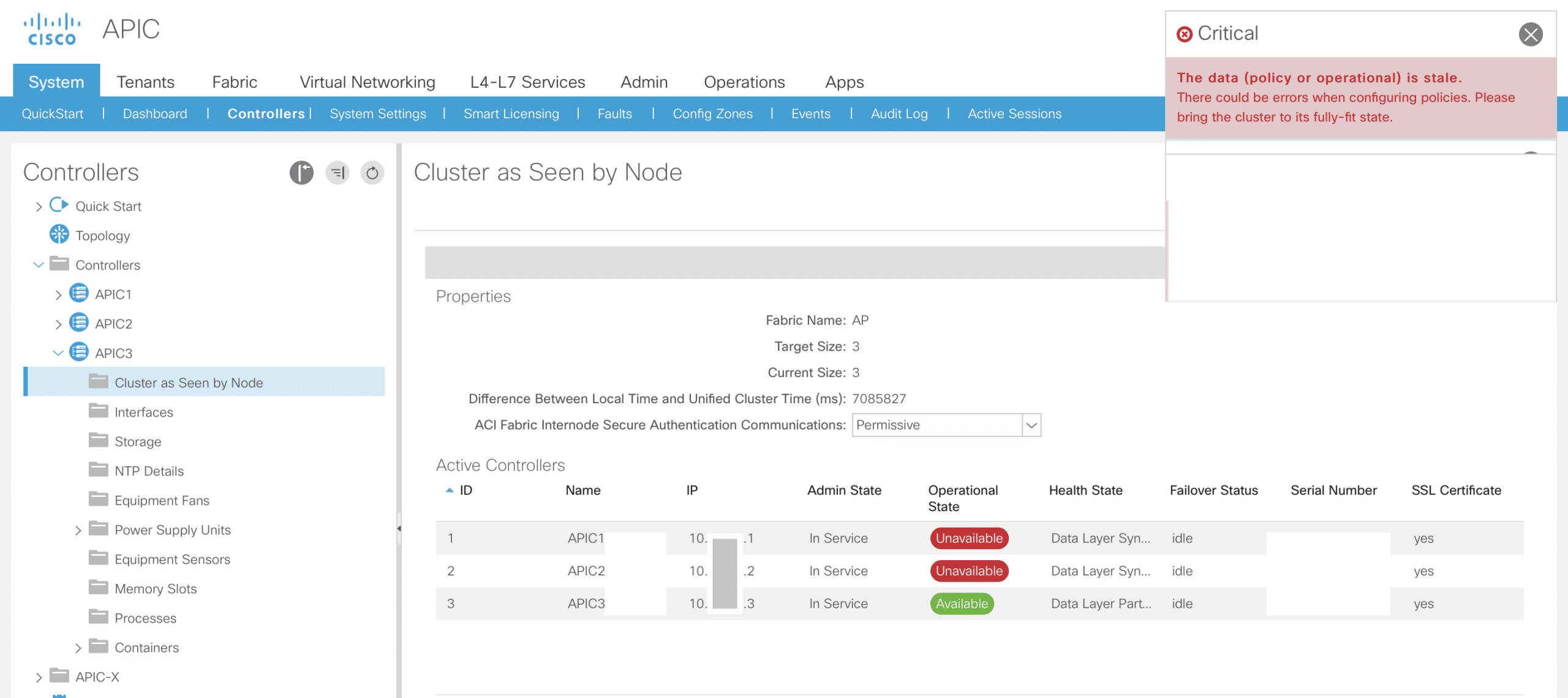
- In our example, we see that all three APIC controllers are up and running before we lose one of the datacenters

- Once we lose the primary location (although I’m hoping for you that this will not happen ever) we see that APICs on primary site are unavailable. If someone tried now to make some configuration changes on third APIC that you are now connected to you would see that an error appears telling you it is not possible to do that.

- Once this happens to your datacenter, in order to be able to configure and manage the remaining site, you need to enable Standby APIC.
Before selecting the replace option we should be sure that APIC which is going to be replaced is decommissioned so that we avoid APIC shreds corruption if the replaced APIC comes back online for some reasons.
Replaced APIC could get back online if we had Split Brain situation with broken datacenter interconnection when that DCI comes back online at an unexpected time.
Another option is that there was some other kind of site failures like a power outage or something which then gets resolved and APICs become active again.
Wiping the replaced APIC is the thing that needs to be done after APIC decommission. If we are getting ready to replace unavailable APIC2 with standby APIC4, like in our example, and we still have some other way to access that APIC2 locally or through some OOB connection, it is a good idea to wait for the decommissioning process to reboot the APIC and then wipe the config from it so that we can prepare that APIC2 to take place of standby APIC instead of APIC4 which was now promoted to active.
You do all of the above steps this way:- Right-click on one of the Unavailable APICs (APIC2 in our example here) and hit the decommission option
- If you are still able to connect to APIC2 after it reboots, wipe the box and configure it as APIC2 Standby:
-
- SSH to that box
- in CLI enter these commands:
#acidiag touch clean #acidiag touch setup #acidiag reboot
- After reboot APIC will get back online as a new wiped APIC which needs to be configured again like it was done when configuring ACI in the beginning, just selecting the option that this is now Standby APIC:
Cluster configuration ... Enter the fabric name [ACI Fabric1]: AP Enter the fabric ID (1-128) [1]: 1 Enter the number of active controllers in the fabric (1-9) [3]: 3 Enter the POD ID (1-9) [1]: 1 Is this a standby controller? [NO]: YES Enter the controller ID (1-3) [1]: 2 Enter the controller name [apic1]: APIC2 Enter address pool for TEP addresses [10.0.0.0/16]: 10.0.0.0/22 Note: The infra VLAN ID should not be used elsewhere in your environment and should not overlap with any other reserved VLANs on other platforms. Enter the VLAN ID for infra network (2-4094): 3967 Enter address pool for BD multicast addresses (GIPO) [225.0.0.0/15]: 225.0.0.0/15 Out-of-band management configuration ... Enable IPv6 for Out of Band Mgmt Interface? [N]: Enter the IPv4 address [192.168.10.1/24]: 10.10.10.102/24 Enter the IPv4 address of the default gateway [None]: 10.10.10.1 Enter the interface speed/duplex mode [auto]: admin user configuration ... Enable strong passwords? [Y]: Enter the password for admin: Reenter the password for admin: admin user configuration ... Strong Passwords: Y User name: admin Password: ******** The above configuration will be applied ... Warning: TEP address pool, Infra VLAN ID and Multicast address pool cannot be changed later, these are permanent until the fabric is wiped. Would you like to edit the configuration? (y/n) [n]: n
-
- When decommission is done right-click on the APIC2 and hit Replace .. this box shows up where you need to select the fourth Standby APIC which will take place of the one APIC that’s unavailable

- After you did that the Standby APIC goes into the reboot and comes up as Active and joins the APIC Cluster with ID of one unavailable Active members

- After the replace was initiated, it is possible that replaced APIC will stay in “working on reprovisioning standby APIC” status for long time and new APIC will not take his place automatically. If that is the case, just hit right click and “commision” on replaced APIC and the process should go through just fine.


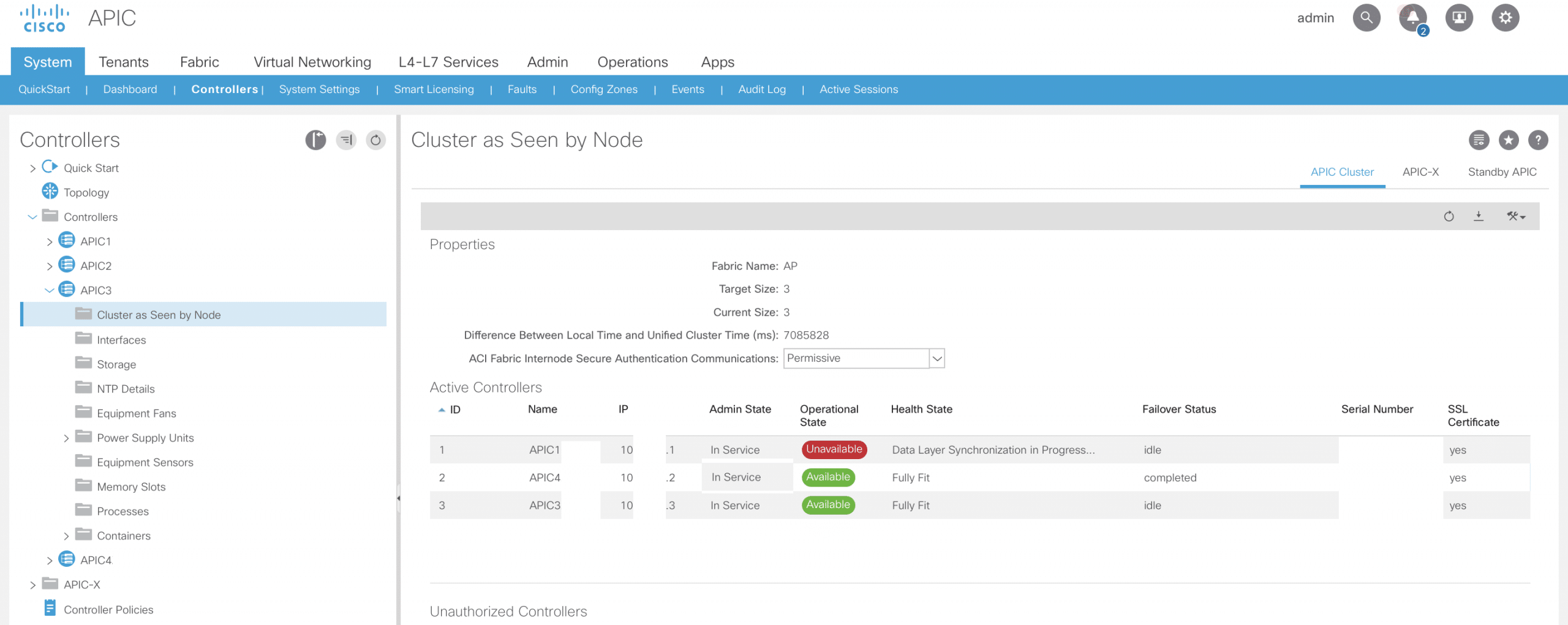
This should be it, now you will have your second ACI datacenter site management plane working completely and you will be able to change a configuration of that ACI Fabric from APIC cluster. The status will be like on the image above.
If you successfully wiped APIC2 and configured it as a Standby, when your primary site gets back online it will get synchronized with active controller cluster on secondary site (APIC4 and APIC3) and you will then have one active APIC1 on primary site and one Standby APIC2 on primary site.

If you decide that you want to get APIC2 back as an active cluster member and APIC4 back to Standby you will have to go through the process described above one more time.
READ MORE ABOUT CISCO ACI:
- Google Jupiter Data Center Network Fabric – New Way of Building Data Center Network Underlay
- Switch vSphere Enterprise Plus license to vSphere Standard on a NSX-T enabled cluster
- NSX-T Edge Transport Node Packet Capture
- VMware NSX-T Install Tips & Tricks
- VMware TKGI – Deployment of Harbor Container Registry fails with error
- Software-defined data center and what’s the way to do it
- What is Cisco ACI?
- CLOS Topology
- Setting up Cisco ACI From Scratch
- New ACI deployment? Watch out when connecting APICs to Leafs
- ACI MultiPod and how to build MultiDatacenter with Cisco ACI
- Cisco ACI – API Calls vs JSON POST
- Cisco ACI – Configuring by POSTing JSON
- How to Advertise a Route from ACI Layer2 BD Outside the Fabric?
- ACI MultiPod – Enable Standby APIC
if primary site is totally disconnected from secondary site ,how can I decommission apic2 from secondary site?
you mean we can visit primary site apic2 from oob , and decommission from there , and wipe config
if we don’t decommission apic2 on site secondary , can we replace apic2 with standby apic?
Lijun,
“you mean we can visit primary site apic2 from oob, and decommission from there, and wipe config” -> Yes!
So the main goal is to avoid getting the intersite communication back up while you have one site with “old” APIC2 still running and “new/replaced” APIC2 on the other site also running. They do not share the IP and name but the replaced APIC takes APIC2’s ID and configuration and having two of them see each order can lead to data corruption on both of them.
“if we don’t decommission apic2 on-site secondary, can we replace apic2 with standby apic?” -> O, Yes!
APIC replace method is one site action and its main purpose is to replace the APIC when the other side APICs (the site with more active APICs) is not available, so yes…
Hey Valter,
with regards to your statement :
“if we don’t decommission apic2 on-site secondary, can we replace apic2 with standby apic?” -> O, Yes!
but if intersite connection returns it still can lead to corruption correct?
cheers
Hi Alex, that’s correct.
You should always decommission the APIC that you replaced with another one so when the DCI comes back up you are sure no corruption will happen..
hope that was the answer you wanted to hear 🙂