Google’s Datacenter Optical Circuit Switches and Jupiter network fabric
Google’s data centers are unlike any other. It seems they have windows like normal houses because as from the last SIGCOMM’22 presentation, they took their SPINE switches and threw them right out of that window.
Google worked on the Micro Electro Mechanical Systems (MEMS) for years in order to build an Optical Circuit Switch (OCS) that would enable dynamic reconfiguration of optical connections between switches in the data center. Optical Circuit Switch enables on-the-fly data center fabric aggregation block switch connections reconfiguration without the need for physical rewiring. And most interestingly, the usage of Software-Defined Networking (SDN) traffic engineering, enables aggregation block switches to be directly connected and completely removes the need for those bulky Spine switches that were connecting aggregation block switches in CLOS topologies.

OCS MEMS mirror array can redirect light from any input port to any output port by slightly moving one of its mirrors and changing dynamically optical connections between aggregation blocks
Spine switch roles are basically replaced with OCS devices for smart, dynamic and direct interconnections of Leafs. SDN is used for BUM traffic handling (Broadcast, unknown-unicast and multicast traffic) that was the other important spine role.
Google paper (Jupiter Evolving: Transforming Google’s Datacenter Network via Optical Circuit Switches and Software-Defined Networking) that was presented at the SIGCOMM’22 conference describes how getting rid of Spines, and smart traffic handling with SDN, enabled the Jupiter fabric to get up to 5x higher speed and capacity and 40% reduction in power consumption in relation to similar CLOS topology datacenter fabrics.
It also shows that hardware upgrades and the scale-out of Jupiter fabric are much easier with OCS. OCS enables aggregation block switches devices addition, draining or removal even if they are of a new generation and different port speed without the need for high-risk and high-cost actions of replacing all Spines (for uplink speed increase) and physical recabling of the fabric, that CLOS fabric implies.
With this paper, the technology behind OCS, which emerged years ago, but was always considered not feasible to be made, just opened a new era of how data centers of the future will get built.
CLOS Topology
As we know, in the classical three-tier CLOS topology Leaf switches are connected/uplinked to Spine switches, providing the same bandwidth 2-hop connections between all the servers connected to Leafs. Spine switches ports speed and capacity dictated fabric wide speed and capacity.
Out with those Spines
Spines are necessary for CLOS fabric. They enable Leaf interconnection and solved BUM traffic optimisation by being the first hop for all inter-Leaf (2 hop) traffic, keeping the map tables of all IP-MAC-VTEP-Leaf-Endpoint information, and learning by flooding.
Spine switches in the data center fabric (according to Google paper) make up to 40% of fabric cost and about 40% of fabric power usage. They are bulky and need to be pre-deployed to enable Leaf switch physical connections. They need to be running the same port speed on all ports to provide uniform bandwidth to all Leaf uplinks.
After some time, new Leafs will need to be added, and a new generation of Leafs will probably support increased port speed, faster speeds than current Spine ports support. With the support of 100G, 200G etc, when connected to 40G Spines, those Spines become bottlenecks for the fabric performance, new Leaf’s uplinks need to be degraded to 40G to function. The next natural step in CLOS fabrics is Spine replacement, and that implies high-cost, high-risk and tedious recabling of data center devices.
OCS – Optical Circuit Switch
OCS is a device that enables dynamic optical signal (light) steering using MEMS mirror arrays to effectively redirect light from any input port to any output port. It doesn’t care about the speed of the lasers that are throwing the signal into its mirrors and it’s theoretically supporting any new optical switch communication speed that can emerge in the future. OCS doesn’t need to be replaced when other network devices connected through it are transitioning from 10G to 40G, 100G, 200G etc.
OCS MEMS mirror array can redirect light from any input port to any output port by slightly moving one of its mirrors and changing dynamically optical connections between aggregation blocks
With the OCS capability mentioned above, Google was able to connect all Leafs (their machine aggregation block switches) to the OCS, and OCS then enabled them (by reconfiguring its MEMS mirror arrays) to configure a full mesh of Leaf switches interconnections getting rid of the need for Spine switches. It was not so easy. OCS is an unbelievable technological and hardware achievement, but someone needs to take care of its dynamic configuration of mirrors and control the BUM traffic issues that Spines were taking care in CLOS architecture.
This further implied a more complex topology and routing control in the fabric than CLOS. Google Jupiter Network Fabric implemented advanced traffic analysis and traffic engineering within their Orion DNS controller. Applied that to fully meshed Leaf topology OCS created with its dynamic topology capabilities, they succeeded to use optimally all Leaf optical interconnections even when they are having different uplink speeds. Even indirect paths through one additional aggregation block (a bunch of leafs) are used when the algorithm calculates that there is enough spare bandwidth on that transit leaf.
Jupiter Network Fabric is able to not only get rid of Spines but also to get rid of the same bandwidth uniform interconnections between Leafs that Spines (and CLOS fabrics altogether) implied. Now the addition of a new generation of Leafs is possible gradually, without the need to replace expensive slower speed spines or leafs. For example, you can connect new 200G capable Leafs to OCS switches where “old” 40G Leafs are connected. OCS will create a full mesh of those new and old leafs and the SDN Orion controller will take new faster links into account when calculating how it will steer traffic that needs more throughput, or traffic that is more delay sensitive. Datacenter fabric then uses some of the 200G interconnects for some types of traffic and some 40G interconnects for some other types of traffic. It’s magic, real-time application traffic patterns are analysed to decide how the full mesh of data center switch interconnections will be optimally used.
How routing loops are cleverly avoided when indirect paths are used, and the details of routing and traffic engineering will be describes in some future article. For now even this descrioption was a major undertaking.
How Jupiter fabric works
First of all, mentioning Leafs is’t a bit wrong to say here. I am using it being mostly involved with deploying small, mostly Cisco ACI CLOS topologies in the past. Google is a bit bigger, so they have ToR switches in their racks (the thing we normally call Leafs) and then they are uplinking those ToR switches to the Aggregation block. Aggregation blocks are made of 4 middle blocks for redundancy and scale, so each ToR switch from the rack is uplinked to all middle blocks. Each middle block is comprised of a full mesh of switches. Inside a Google data center, each aggregation block was the piece that was connected to spines in a CLOS topology, 5 or more years ago. Today, those aggregation blocks are the components that are interconnected through multiple OCS devices in the Jupiter block-level direct-connect topology and don’t need any spines.

Aggregation blocks are made of 4 middle blocks for redundancy and scale, so each ToR switch from the rack is uplinked to all middle blocks
So basically, having OCS devices enables Google to create a directly connected topology where traffic is then optimally forwarded by dynamic traffic and topology engineering.
In the image below we see two aggregation blocks connected with 512 uplinks each to 4 clusters of OCS devices which by adjusting their MEMS mirrors configure 512 direct optical duplex connections between those two blocks.
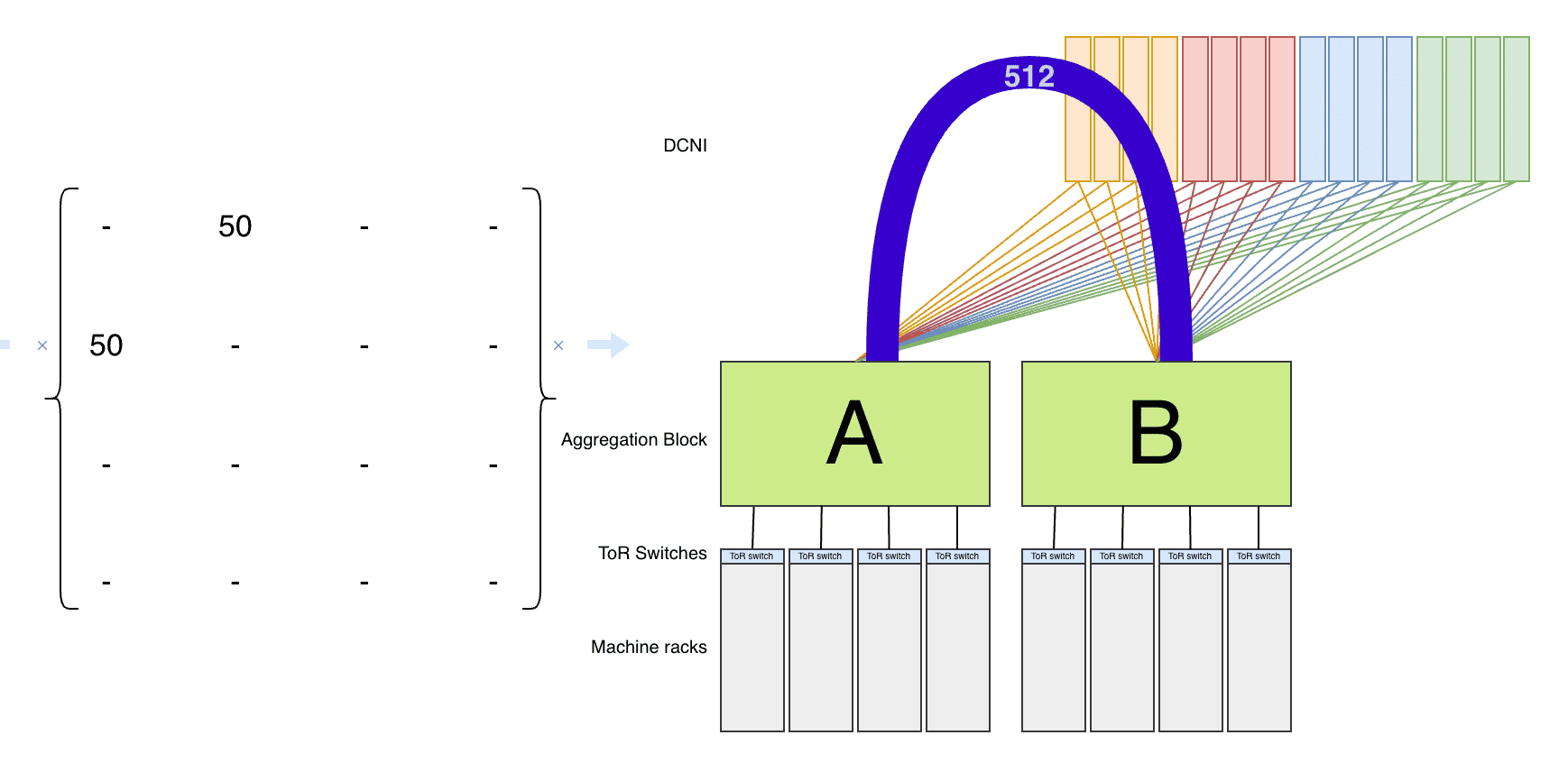
Aggregation Blocks with 512 uplinks
When block C is added by deploying additional 512 fibers to the OCS devices. OCS performs topology engineering (adjusts mirrors into position) which forms a mesh topology shown below. It’s visible that half of the uplinks from blocks A and B were changed on OCS to point to block C.

Aggregation block C is wired and added to the topology
At this point flow measurements start to take the servers connected to block C into account. Flow measurements are done in such detail that at the end Orion SDN has the traffic matrix data of the total number of packets sent from one block to the other in the last 30 seconds. This matrix is then used to form a predicted traffic matrix which is used for WCMP optimisation (Weighted Cost Multipathing).
So basically, Traffic Engineering kicks in and optimises WCMP weights across different paths using real-time data, avoiding over-subscription of blocks. It also enables the use of direct (red arrow) and indirect traffic paths (cyan arrow) between blocks giving the indirect path less weight based on current transit block throughput availability.

Traffic Engineering – WCMP
After some time, block D needs to be added. But there are not too many racks connected to it at the moment so only 256 uplinks will do for the time being. OCS adjusts the uplinks of block D to be evenly connected with the almost same number of links to all other three blocks A, B and C.

Block D added to the aggregation block with 256 uplinks to OCS
When block D racks get populated with more machines, more uplinks are needed for block D. Block D get an additional 256 connection to OCS with a total od 512 like other blocks. OCS reconfigures the connections to other blocks based on the traffic needs towards other racks connected to other blocks.

Block D with 512 uplinks
After some time, a new generation of network ToR and aggregation block switches get to the market and Google decides that blocks C and D will get new switches with 200G capability, unlike blocks A and B which are running 100G interfaces. OCS leave the physical topology the same but traffic engineering gives more weight to direct links between block C and D which can then leverage 200G link speed for direct transit traffic.

Blocks C, D upgrade to 200G
Optical Circulators – one fiber per duplex connection
Is a masterpiece of physics. It’s a passive device that enables bidirectional optical signal flow through one fiber only. It can be used with multiple generations of SFPs being only connected as a passive device between SFPs and the OCS switch. It takes light received from SFPs laser (Tx) and “circulates” them through crystals, rotators and polarizers to push them into the optical fiber, at the same time it receives the light signal from that same fiber and “circulates” it out into Rx signal towards SFPs. The process is doubling the number of connections OCS can support enabling one fiber for each duplex connection. Without circulators, components of OCS will more than double.