ACI MultiPod – Enable Standby APIC

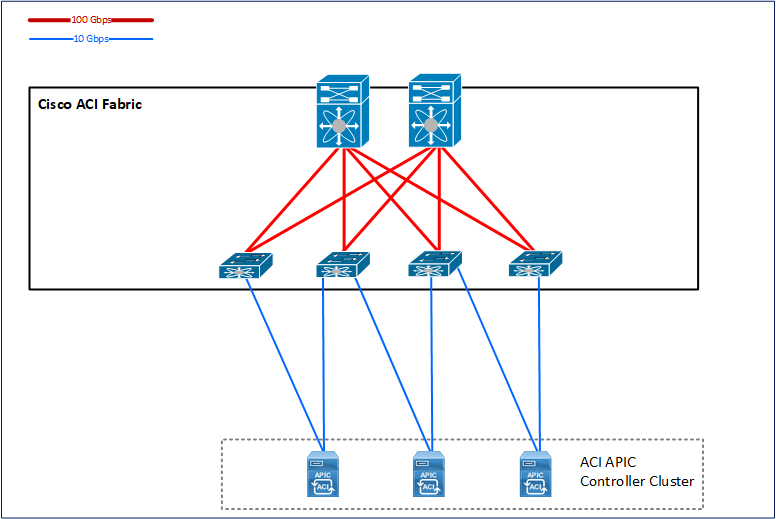
APIC Controller Cluster
You actually need three APIC controller servers to get the cluster up and running in complete and redundant ACI system. You can actually work with only two APICs and you will still have a cluster quorum and will be able to change ACI Fabric configuration.
Loosing One Site
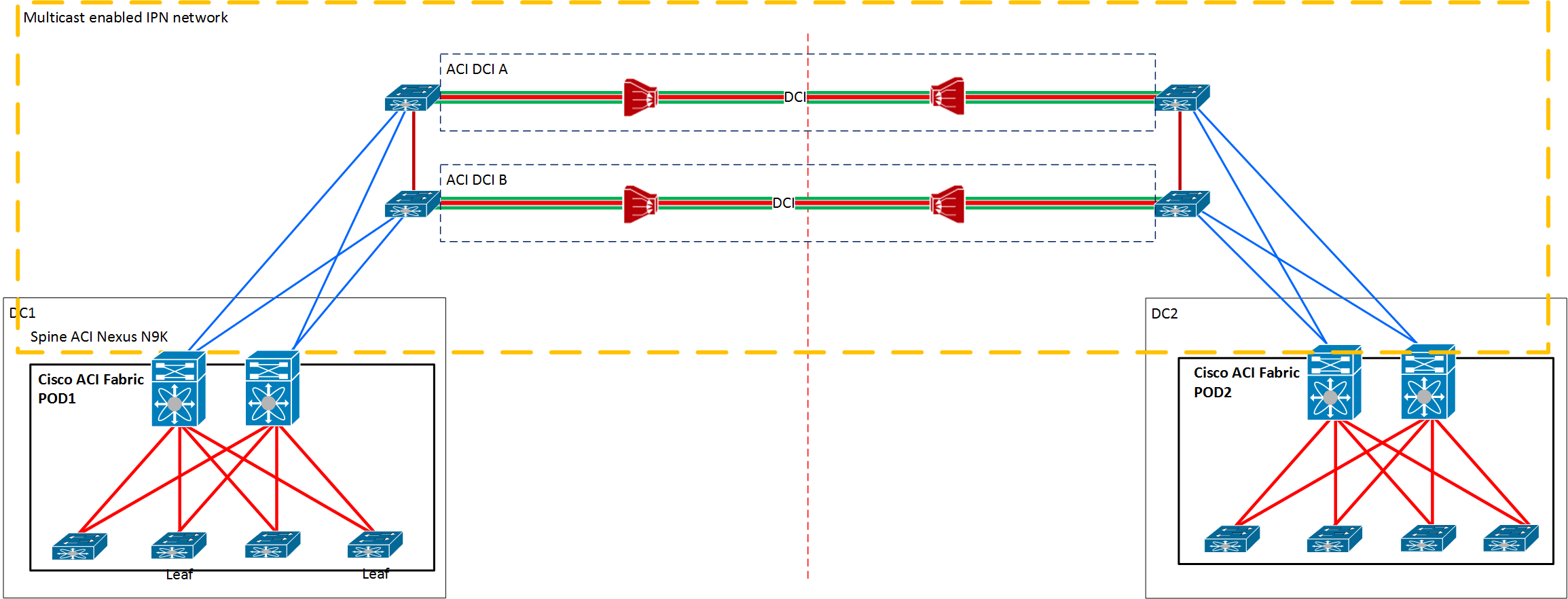
In the MultiPod, those three controllers need to be distributed so that one of them is placed in the secondary site. The idea is that you still have a chance to keep your configuration on one remaining APIC while losing completely primary site with two APICs. On the other hand, if you lose secondary site, two APICs in the first site will still enable you to do configuration and management of ACI Fabric as nothing happened.
Losing DCI Interconnect
The second type of MultiPod fail is when you lose DCI (datacenter interconnect). In that case, both sites will keep working but will alert that the other side is down. The secondary site with one APIC will be in read-only mode and the primary site will be fully functional with two remaining APICs on that site. If some changes are made on the primary site, those changes will be replicated to the third controller on the secondary site when DCI recovers and configuration relating site B POD will be then pushed to POD 2 fabric.
DCI issues are not a good time for APIC replacement, just wait for DCI to start working normally and continue to use ACI APIC controllers as before the issues. You will still have the option to manage primary site if DCI fails and after DCI starts working again changes will be replicated to secondary site APICs and Fabric.
Please note that temporary DCI issues are not a good time to replace the APIC. If you are experiencing just a DCI outage the second site still works but it cannot be configured. Think about it, perhaps the best thing to do in this case is not to change the configuration of your fabric on either side while DCI doesn’t get back up and running. That way you are sure your configuration does not affect the MultiPod stability once DCI gets back up and sites start to communicate again.