Edson Erwin invented this highly scalable and optimized way of connecting network nodes in the 1930s and Charles Clos made the telephone nodes interconnection design using that solution. It was even before we had IP networks. He invented it in order to optimize the architecture of telephony network systems back then.
It was not used in IP based network for last few decades but it experienced a big comeback with new datacenter design in the last few years. It was first invented only for scalability requirements that it solved beautifully. In new datacenter design, CLOS topology of interconnecting network devices scalability is also the first requirement that gets solved, but it also greatly helps with improving resiliency and performance.
In today’s datacenters, CLOS topology is used to create Leaf’n’Spine system of interconnecting Leaf switches (datacenter access switches or ToR switches) together through Spine switches. It is created in a way that each Leaf switch is redundantly connected to all Spine switches directly.
As it is shown in the picture below, in this way, using CLOS topology, we are interconnecting Leaf switches in a way that they always have only two hops between each other and this done redundantly as two hops through each Spine switch. Spines are not directly connected and Leafs are also not directly connected.

In network datacenter network topology like this, servers are connected only to Leaf ports and Spines are only used to interconnect Leafs and keep endpoint Leaf to Endpoint MAC to Endpoint IP mapping tables in order to optimize L2 and L3 forwarding. In SDN solutions for datacenter like Cisco ACI, the whole system is centrally deployed and managed using special controller cluster which pushes the configuration to each member (leaf and spine) and the system like that is then called Fabric.
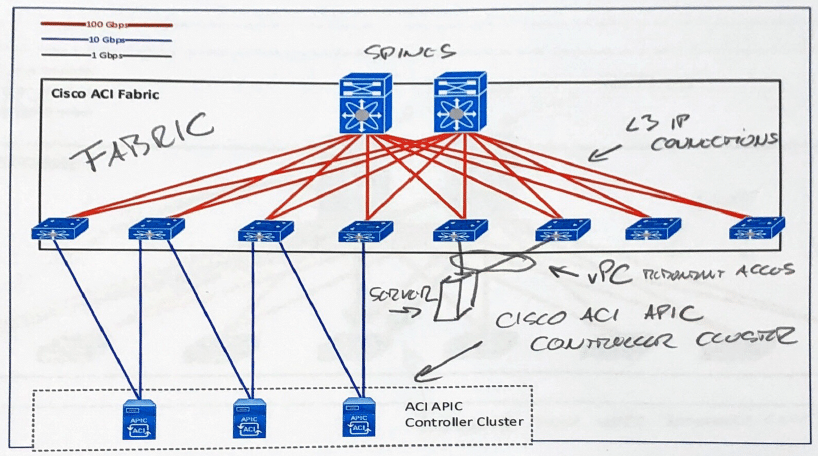
In Leaf and Spine topology, when servers are connected to different leaves, they always have three hops between them. First hop from server to leaf, the next through the Fabric Spines towards the destination Leaf and the third from destination Leaf to the destination server. It is the same thing is the servers are in the same L2 segment or in different ones.
Having equidistant endpoints in the whole datacenter enables us to have the same latency between all servers and increases the stability and performance of network communication.
On the other hand, if one Leaf or Spine fails, the bandwidth will be degraded but the communication between all vPC connected servers in the whole fabric will still be possible.
Bonding more access ports from different leafs is still possible (Multi-chassis EtherChannel or vPC virtual port channel). It is done by connecting the server to two Leafs and configuring vPC in order to be able to survive Leaf malfunction. In this way, servers are redundantly connected. vPC peer links and similar stuff that before Leaf and Spine Fabrics meant you needed to interconnect two switches in between them in order to enable multi-chassis EtherChannel, is now resolved differently (by not connecting them together) but sending vPC peer communication and all that stuff through Spine switches.
CLOS is great in scaling out (horizontal scale). All the uplinks between Leaf and Spines are always used by leveraging L3 ECMP Routing/Forwarding (Equal Cost Multipath) and even the L2 traffic which before needed Spanning Tree to fight against the loops, is now encapsulated (in VxLAN or Geneve) and Routed through the fabric leveraging ECMP and avoiding the need for Spanning tree protocol altogether (which avoids disabling redundant uplinks and using full fabric interconnect bandwidth).
If servers need more bandwidth between them, CLOS Fabric make is easy to upgrade, is simply means adding more Leaf to Spine links or adding one or more Leaf and Spine devices in the fabric. In Cisco ACI case, where everything is controlled and deployed from the central controller, adding Spines and Leafs is done simply and provisioning of new devices is done automatically by registering them to fabric and waiting for the controller to provision them as part of it.
Usually, Leaf to Spine links are nowadays 40G or 100G Ethernet which makes Leaf to Leaf bandwidth at 200G in the fabric. If the Leafs are more or less all 48 port 10G access port devices you get 1:2,4 ratio between downlinks and uplinks which is quite great. Next generation of Fabric will move to 400G interfabric connections making the fabric interconnect superfast.
READ MORE ABOUT CISCO ACI:
- Google Jupiter Data Center Network Fabric – New Way of Building Data Center Network Underlay
- Switch vSphere Enterprise Plus license to vSphere Standard on a NSX-T enabled cluster
- NSX-T Edge Transport Node Packet Capture
- VMware NSX-T Install Tips & Tricks
- VMware TKGI – Deployment of Harbor Container Registry fails with error
- Software-defined data center and what’s the way to do it
- What is Cisco ACI?
- CLOS Topology
- Setting up Cisco ACI From Scratch
- New ACI deployment? Watch out when connecting APICs to Leafs
- ACI MultiPod and how to build MultiDatacenter with Cisco ACI
- Cisco ACI – API Calls vs JSON POST
- Cisco ACI – Configuring by POSTing JSON
- How to Advertise a Route from ACI Layer2 BD Outside the Fabric?
- ACI MultiPod – Enable Standby APIC